
I’ve already talked about how to potentially obtain the dimensions of a conceptual space with artificial neural networks in a previous blog post. That approach is based on machine learning techniques, but there’s also a more traditional way of extracting a conceptual space: Conducting a psychological experiment and using a type of algorithm called “multidimensional scaling”. Today, I would like to give a quick overview of this approach.
Conceptual spaces provide a geometric way for representing the similarity of different objects: Each object is represented by a point in the conceptual space and the distance between two points reflects the conceptual distance between the two underlying objects.
Whenever you’re unsure about the structure of the conceptual space for a given domain, you can try to investigate how this space looks like by eliciting similarity ratings from humans. Based on these similarity ratings, you can then in some sense “reverse-engineer” the underlying conceptual space.
Let’s assume that we’re interested in a conceptual space for fruit. We can either manually define the dimensions of this space (based on our best guesses for relevant features in this domain) or we can base it on human similarity ratings. In the latter case, we would conduct a psychological study where we ask participants to report the relative similarity of different types of fruit. There are different variants of doing this and I won’t describe them in detail. In one of the basic methods, participants are presented with pairs of stimuli (in our case pairs of fruits, e.g. “apple – pear”) and are asked to indicate how different those two stimuli are on a given scale (ranging for instance from zero to five indicating the range from “identical” to “very different”).
These conceptual distance ratings are then averaged across all participants of this study. You then end up with a so-called “distance matrix” as depicted in Figure 1:
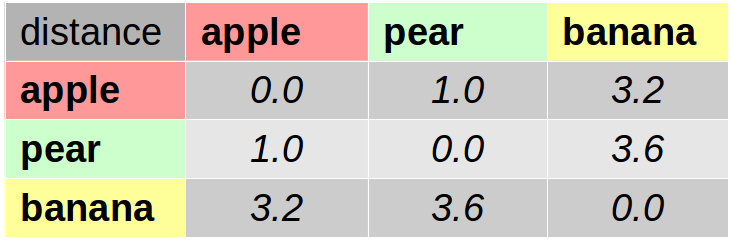
This distance matrix contains for each pair of stimuli (in our case “apple”, “pear”, and “banana”) their average distance as reported by the participants. In our example, the conceptual distance between “apple” and “apple” is 0.0, indicating that the “apple” concept is identical to itself. The distance between “apple” and “pear” is 1.0, which indicates that “apple” and “pear” are quite similar, but not the same thing. The distance between “apple” and “banana” is 3.2, indicating that they are not completely unrelated, but still relatively different from each other.
Okay, so now we got these measures of conceptual distance, but how does the underlying space look like?
This is where multidimensional scaling enters the stage.
Multidimensional scaling (MDS) is a technique that takes as input a distance matrix and the desired number n of dimensions and produces as output an n-dimensional space. Each stimulus from the distance matrix is represented as a point in this n-dimensional space and the MDS algorithm tries to arrange these points in such a way, that the pairwise distances between these points are as close as possible to the pairwise distances in the distance matrix.
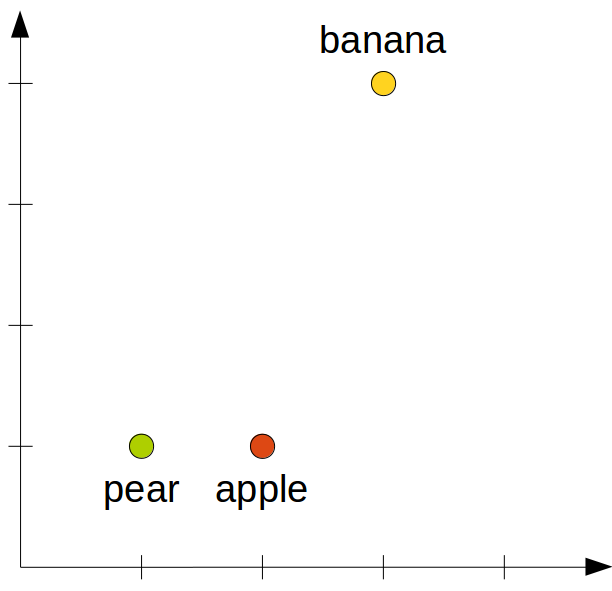
Figure 2 shows one possible result of the MDS algorithm: “pear” has the coordinates (1,1), “apple” has the coordinates (2,1), and “banana” has the coordinates (3,4). As you can easily check, the distances between these points accurately reflect the distances from the distance table in Figure 1.
However, this is not the unique solution. Also the space shown in Figure 3 is a valid solution as it also correctly reflects the distances:
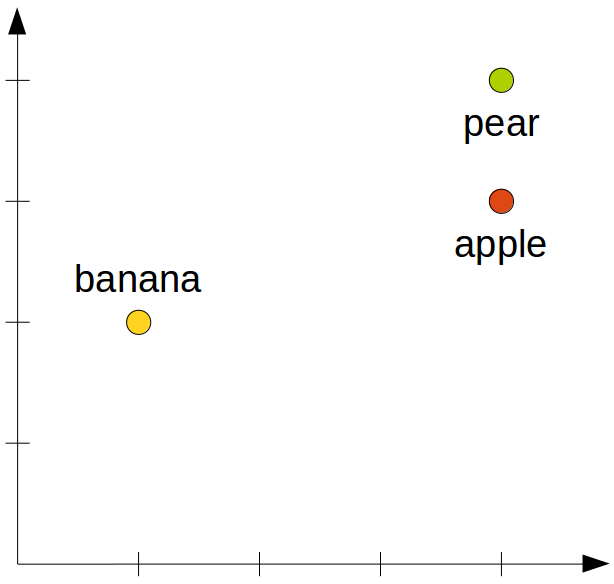
Moreover, conceptual spaces generated by multidimensional scaling do not necessarily have interpretable dimensions – after all, we can rotate all the points around the origin without changing their relative distances.
Furthermore, in order to run the MDS algorithm, we need to already know how many dimensions we need for our conceptual space. In our simple example, a two-dimensional space was already able to accurately reflect the cognitive distances. However, we could have also used a one-dimensional or a three-dimensional space. Choosing the right number of dimensions can be quite tricky in practice and is a limitation of this approach.
Finally, MDS is only applicable to the stimuli from the distance matrix – if for instance a new type of fruit comes along (such as orange or pineapple), we have no clue where its corresponding point should be located in the conceptual space. In more technical terms, we can say that the mapping does not generalize to unseen inputs. For a practical AI system, this generalization capability is however very important. After all, we would like our AI system to do something reasonable even when it encounters previously unknown objects.
Despite of these shortcomings, MDS is still a very important technique in research on psychophysics, because it can help us to use the results of psychological experiments in order to get an idea of the underlying conceptual space. The spaces produced by MDS are thus psychologically grounded – unlike the ones obtained by artificial neural networks.
Hmm. Given its shortcomings, I’m not convinced that MDS is useful for finding a domain; however, it may be useful for confirming the property relationships of an existing domain. For example, Gardenfors talks about the color domain. If my memory serves, in his first book he shows the three-dimensional domain of color and how psychology experiments confirm his predictions.
I agree – you usually already have to have some kind of hypothesis in order to make sense out of the results provided by MDS.